J'ai récemment remarqué (grâce au cache de formulaires de Chrome) que les captchas de connexion AliExpress n'étaient pas aléatoires. Il semble qu'ils utilisent un ensemble d'images pré-générées et envoient aux utilisateurs une image aléatoire issue de cet ensemble. Ce n'est, bien entendu, pas la bonne manière d'utiliser des captchas, surtout si l'on ajoute le fait que ce sont des captchas textuels, assez faciles à résoudre par OCR.
Mon objectif ici n'est pas de démontrer une attaque réussie contre le formulaire de connexion d'AliExpress, mais plutôt de présenter un simple PoC démontrant les faiblesses de ces captchas.
J'ai signalé cette vulnérabilité à AliExpress via leur programme de bug bounty.
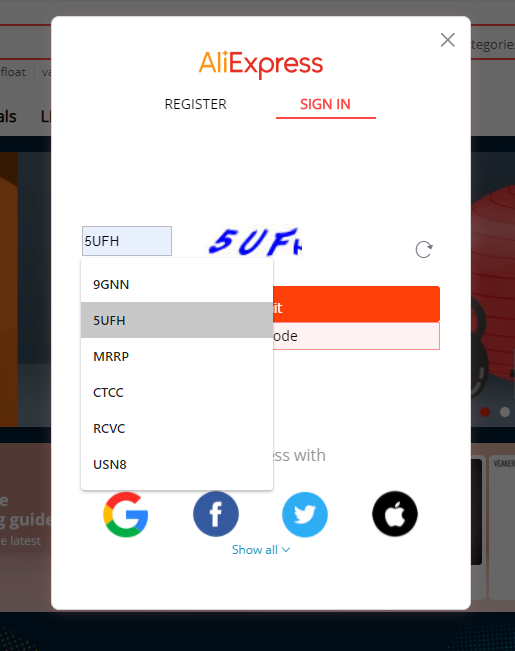
Construire une table de captchas connus
La première étape était de savoir si la requête de captcha nécessitait une authentification. Voici la requête originale interceptée par le proxy :
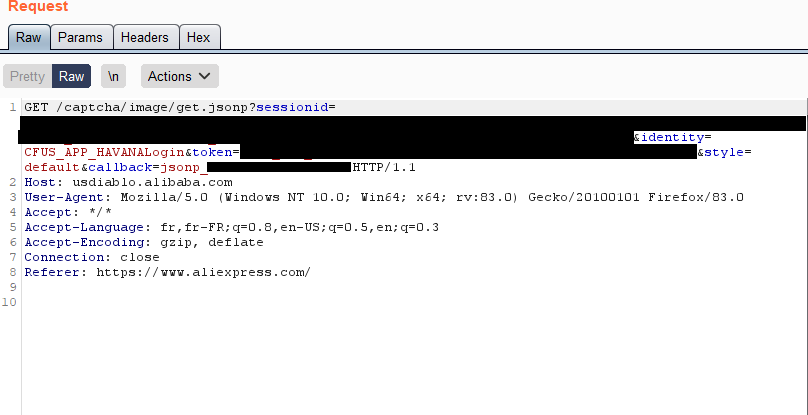
L'une des premières choses que je fais en examinant une requête est de retirer manuellement chaque paramètre GET ou POST, et chaque en-tête HTTP, afin de distinguer ceux nécessaires à l'application des autres. Dans ce cas, certains paramètres sont nécessaires, mais ils n'ont pas besoin d'avoir une valeur valide. Nous utilisons la requête suivante pour obtenir les captchas :
GET /captcha/image/get.jsonp?sessionid=random&identity=data&style=default&callback=callback HTTP/1.1
Host: usdiablo.alibaba.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0
Accept: */*
Accept-Language: fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: close
Referer: https://www.aliexpress.com/Les captchas reçus contiennent toujours 4 caractères alphanumériques en majuscules :

On peut les résoudre avec tesseract :
tesseract --psm 8 captcha.jpg - --dpi 100
— MRRPIl existe des moyens d'améliorer la précision de tesseract en modifiant l'image. Voici deux transformations basiques :
convert captcha2.jpg -type grayscale -quality 100 -density 300 grayscale.jpg
convert captcha2.jpg -level 50% -quality 100 -density 300 contrast.jpgDans ce cas, cela n'a pas vraiment aidé, mais c'est une bonne astuce à garder en tête pour le traitement de captchas.
Pour rendre le processus plus efficace, on peut optimiser le temps de recherche des captchas et sauvegarder les résultats pré-calculés. Un problème est rapidement apparu : deux images similaires avaient des checksums différents (je voulais utiliser le MD5 de l'image pour l'indexation). J'ai creusé un peu plus pour comprendre pourquoi ces images, pourtant identiques pixel par pixel, étaient différentes :
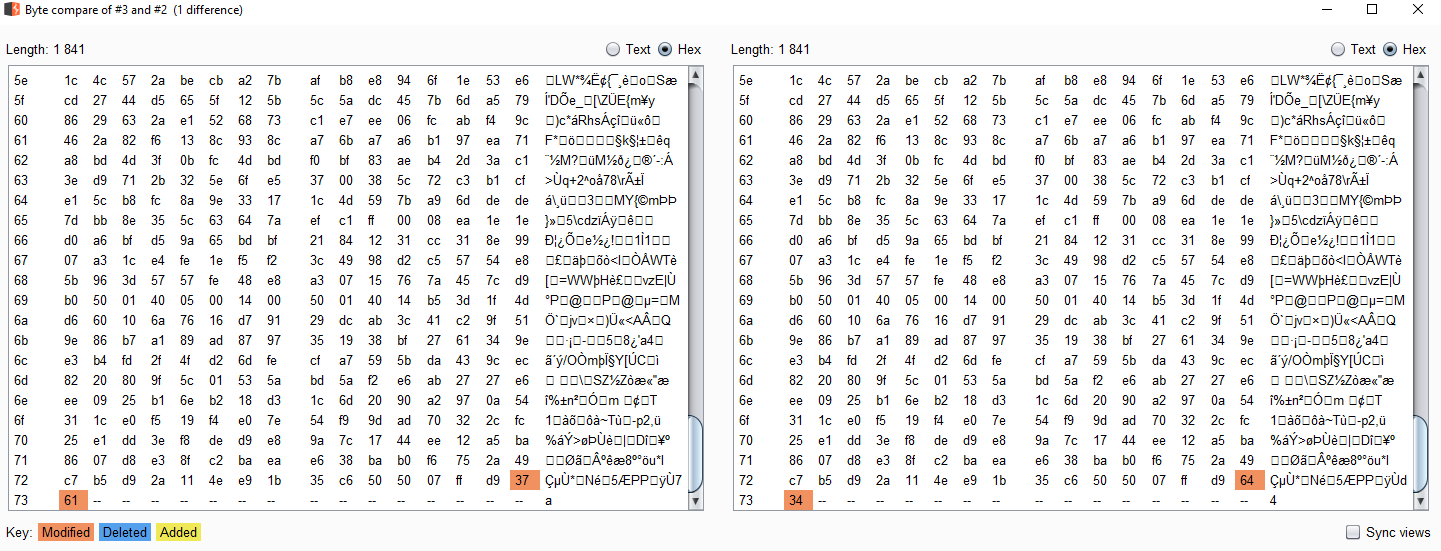
Le serveur génère des images différentes en modifiant les deux derniers octets de l'image ! Il ajoute en réalité un octet aléatoire encodé en hexadécimal. Les modifications sont impossibles à percevoir, n'ont aucun impact sur l'image, mais les hashs diffèrent. La raison est que FF D9 marque la fin du fichier JPG — les octets qui suivent peuvent être ignorés.
J'ai opté pour une méthode plus simple pour indexer mes fichiers : le nombre d'octets aléatoires est toujours le même, et les images affichant des captchas différents ont des tailles différentes. Je peux donc indexer mes images par leur taille en octets !
capt_hash[1571] = "7FKT"
capt_hash[1749] = "9GNN"
capt_hash[1799] = "DBPR"
capt_hash[1818] = "UH9G"
capt_hash[1841] = "RCVC"
capt_hash[1867] = "MRRP"
capt_hash[1900] = "EFU2"
capt_hash[1927] = "USN8"
capt_hash[1935] = "BWSJ"
capt_hash[1965] = "5UFH"En résumé, plus besoin de résoudre le captcha — la taille du fichier image reçu suffit à connaître la réponse attendue !
Limitations
La résolution automatique des captchas par tesseract n'est pas très précise pour le moment. Construire le dictionnaire manuellement n'est pas très difficile car le nombre de captchas est très limité. Mais pour aller plus loin, la méthode OCR doit être améliorée.
Il semble y avoir des protections supplémentaires sur ce formulaire, que je n'ai pas explorées. En effet, lors de l'envoi de la réponse au captcha, il est aussi attendu d'envoyer un paramètre nommé captchaToken :
{"answer":"DBPR","captchaToken":"S10bb4dcdf0b3252825a76f4f803310a277f618d6b..."}
Ce token accompagne le fichier image du captcha, et n'empêche pas réellement la soumission automatique du formulaire. Il existe de nombreux autres paramètres en jeu dans ces requêtes (comme une signature par exemple) et ne connaissant pas leur rôle exact, je ne les mentionnerai pas ici.
Conclusion
Bien qu'aucun exploit tangible ne découle directement de cette étude, je trouve intéressant d'examiner la manière dont AliExpress génère ses captchas. Il est important de noter l'effort d'ajouter deux octets aléatoires après le EOI dans les JPEG des captchas, comme tentative de rendre chaque fichier unique et probablement contrer les vérifications par checksum. Un usage potentiel de cette découverte — résoudre les captchas rapidement et de manière déterministe — serait de s'intégrer dans un processus complet d'automatisation d'inscription ou de connexion.
Références
Restez classe, amateurs de cybersécurité !
Besoin d'un audit de sécurité ou d'un accompagnement sur mesure ?
Découvrir nos services →