C'était la première fois que je devais affronter du code virtualisé, donc ma solution est loin d'être la meilleure. Il existait sûrement des méthodes bien plus rapides, mais la mienne a fonctionné. Ce write-up est principalement destiné aux débutants dans le domaine du reverse engineering de code obfusqué.
Type de challenge
Il s'agit d'un challenge de type keygen. Il faut télécharger un binaire qui prend des entrées et, à la manière d'un logiciel sous licence, vérifie ces entrées l'une contre l'autre. L'objectif est de créer un keygen : un script qui génère des entrées valides pour l'algorithme de vérification. Il y a deux entrées : un nom d'utilisateur et un numéro de série.
./keykoolol
[+] Username: toto
[+] Serial: tutu
[!] Incorrect serial.Dans ce type de challenges, je conseille de fuzzer manuellement les entrées. En envoyant des caractères spéciaux et des chaînes de longueur invalide, vous pourriez obtenir des messages d'erreur intéressants. La première étape est de comprendre ce que le logiciel attend comme entrées.
Analyse ELF
Le fichier est un ELF de 16 Ko :
keykoolol: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
for GNU/Linux 3.2.0, strippedLes sections révèlent des choses plus intéressantes :
[14] .text PROGBITS 0x730 0x1ce2 AX
[16] .rodata PROGBITS 0x2420 0x4c0 A
[24] .bss NOBITS 0x3020 0x2868 WA.text contient notre code, mais .rodata et .bss sont étonnamment volumineux. 1216 octets pour .rodata et 10 Ko pour .bss ? Quelque chose cloche. Pour rappel, .bss est destiné aux variables globales non initialisées — il contient souvent des clés de chiffrement de session et des données d'exécution.
Après l'offset 0xC0 dans .rodata, les données semblent incompréhensibles — mais sont-elles aléatoires ? Analysons l'entropie avec binwalk -E :
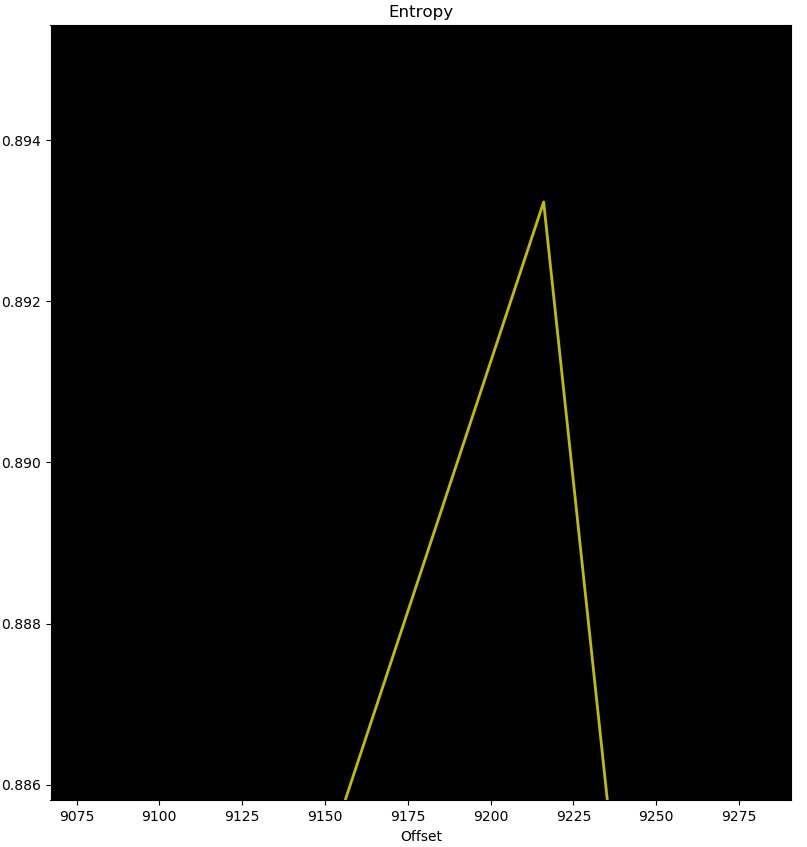
L'entropie est d'environ 0.894 — insuffisant pour qualifier ces données d'aléatoires. L'octet NULL revient très souvent, le pattern 0006 apparaît quatre fois, et 0c00 apparaît deux fois. Pour comparaison, des données réellement aléatoires :
Désassemblage du binaire
La fonction main :
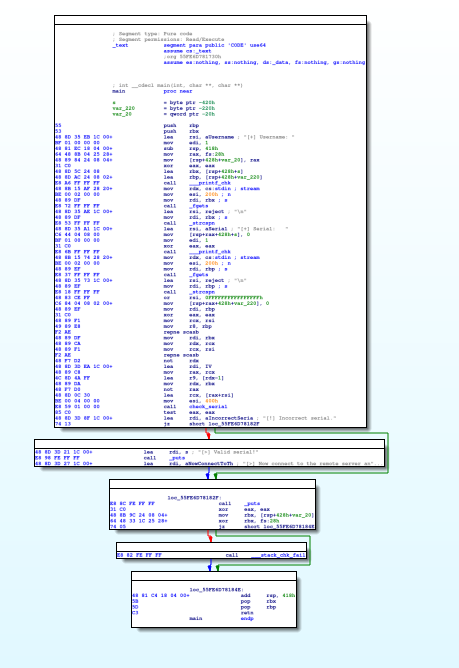
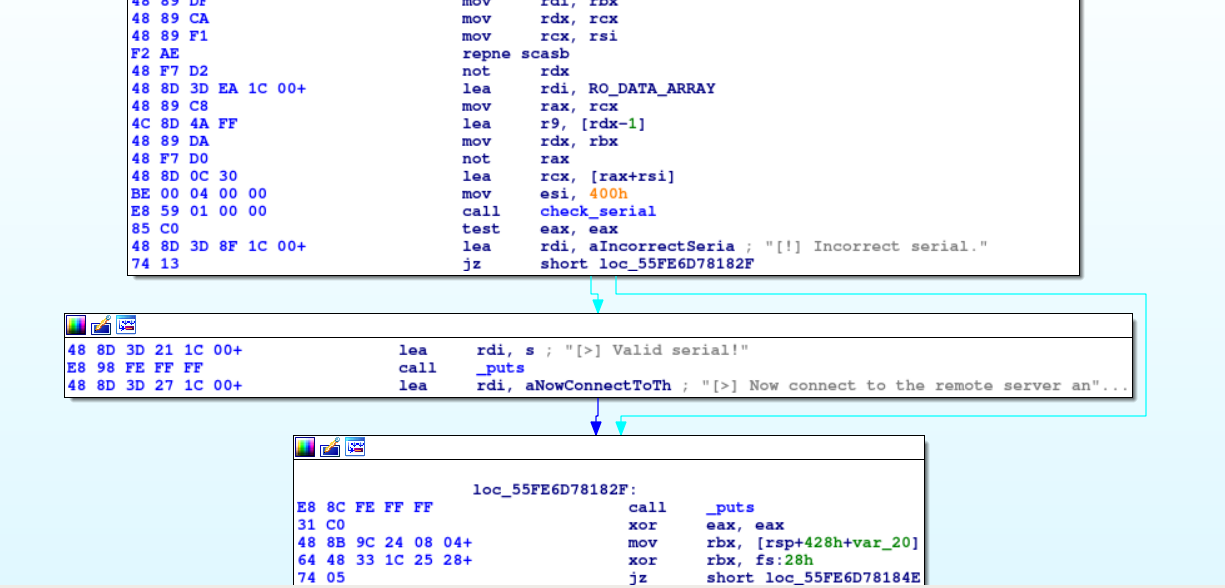
Passons au plat principal — la fonction check_serial :
La fonction prend RO_DATA_ARRAY en argument, qui est copié (0x400 octets) dans le .bss :

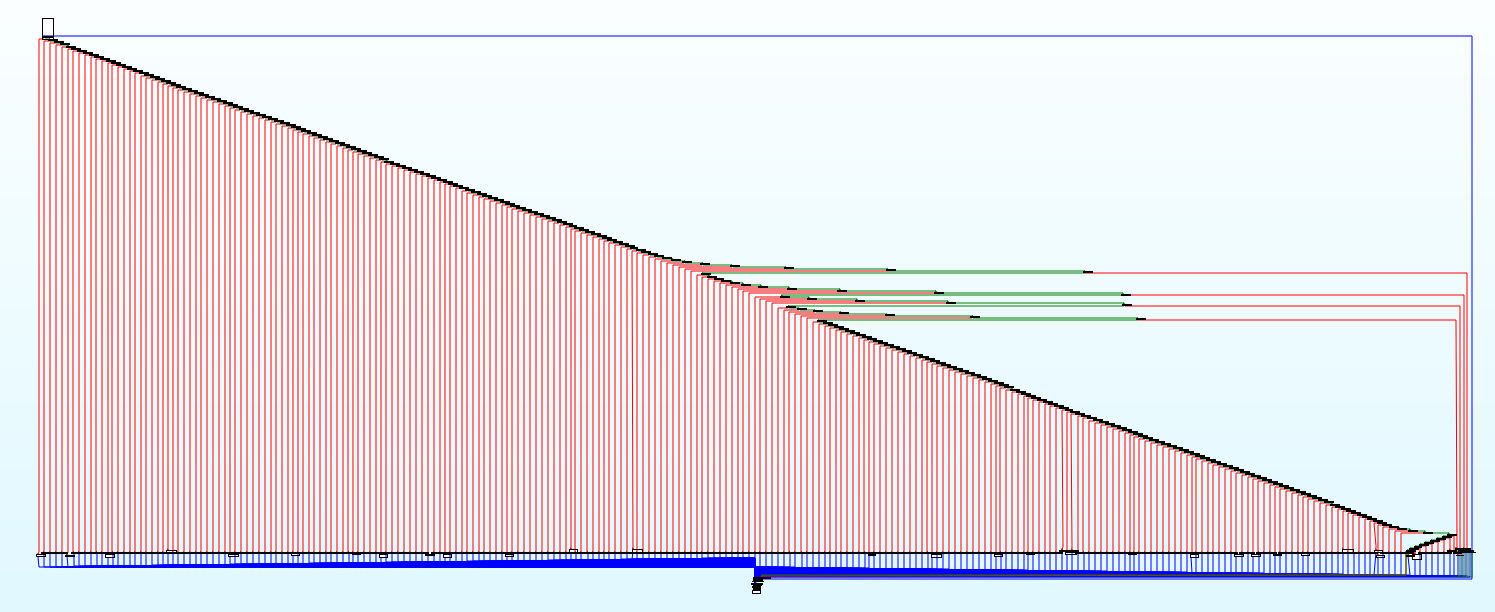
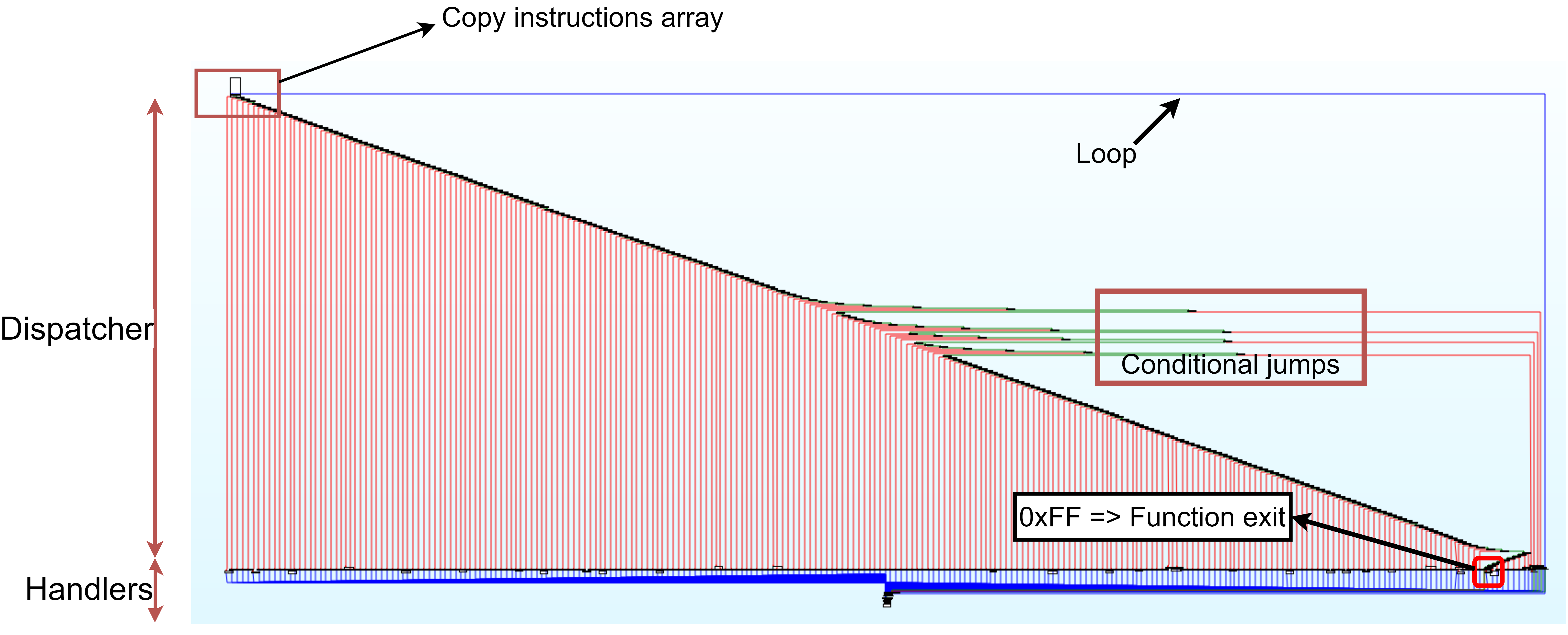
Le cœur est une boucle sur toutes les valeurs du tableau, prises comme des dwords, vérifiant l'octet de poids faible — une structure switch-case à 256 cas :

Vous avez sous les yeux un processeur virtuel, qui interprète un bytecode personnalisé, également appelé Représentation Intermédiaire (IR). Le code original a été découpé en blocs de base et traduit dans un code de plus haut niveau.
Les sauts conditionnels partagés par tout le code :
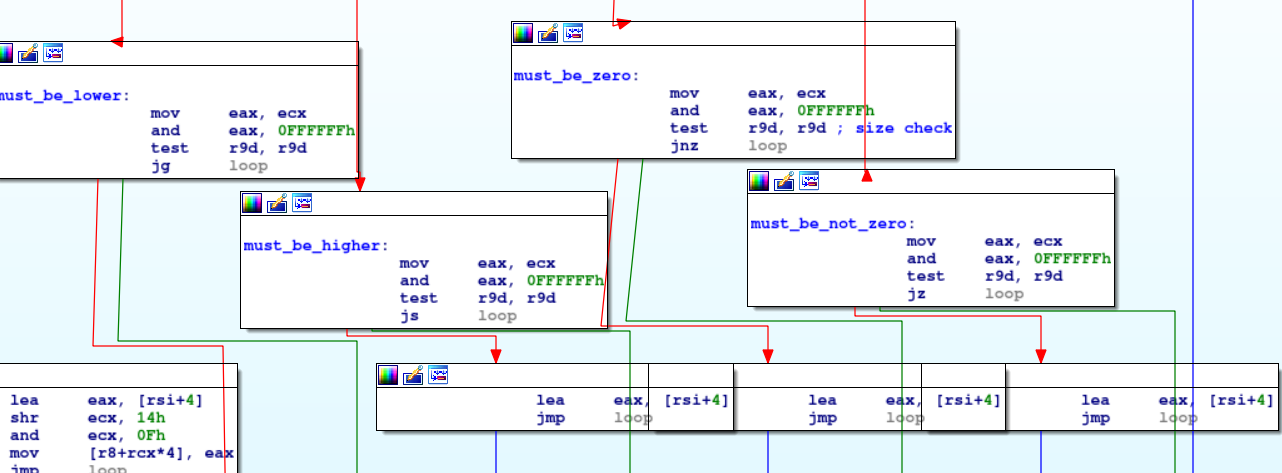
Traduction IR vers x86 pour les sauts conditionnels :
0x15: sauter si supérieur (doit être inférieur)0x14: sauter si inférieur (doit être supérieur ou égal)0x0A: sauter si non nul (doit être égal)0x09: sauter si nul (doit être différent)
Le code est également auto-modifiant — d'où la copie dans le .bss accessible en écriture. Il y a trois étapes de désobfuscation par XOR. Après désobfuscation complète de l'IR, les étapes macroscopiques sont :
- Vérifier le charset du serial
- Hasher le nom d'utilisateur
- Décoder de nouvelles instructions avec
C1D2E3F4 - Décoder le serial hexadécimal
- Décoder de nouvelles instructions avec
A1B2C3D4 - Chiffrer 32 tours d'AES
- Décoder de nouvelles instructions avec
AABBCCDD - Boucler sur le serial et vérifier octet par octet
Hachage du nom d'utilisateur
La fonction de hachage en IR :
0x0e 3 0d 658 -> (username[i]+j)*0D
0x13 3 25 0e7 -> (username[i]+j)*0D ^ 25
0x11 3 ff 64b -> ((username[i]+j)*0D ^ 25) % FF => resRéimplémenté en Python :
def derived_key(tkey):
s = tkey
for k in range(0, 5):
s += ''.join(chr(((ord(s[i+(k*16)])*0x03)^0xFF)&0xFF) for i in range(0,16))
return s
def transient_key(username):
temp = ('00'*16).decode('hex')
for i in range(0, len(username)):
temp2 = ''.join(chr((((ord(username[i])+j)*0x0D)^0x25)%0xFF) for j in range(0, 16))
d = deque(temp2)
d.rotate(i)
temp = ''.join(chr(ord(temp[k])^ord(list(d)[k])) for k in range(0, 16))
return tempAvec un nom d'utilisateur donné, on obtient le même hash que le binaire avec derived_key(transient_key(username)).
Crypto — là où ça devient amusant
Résumé :
- Le serial doit être une chaîne hexadécimale de 0x80 octets
- Le nom d'utilisateur est hashé en 0x60 octets
- Les deux dernières lignes de 16 octets du serial sont des clés de chiffrement

Le code chiffre le serial avec l'instruction AES-NI aesdec sur plusieurs tours, puis vérifie octet par octet que le résultat est égal au hash :
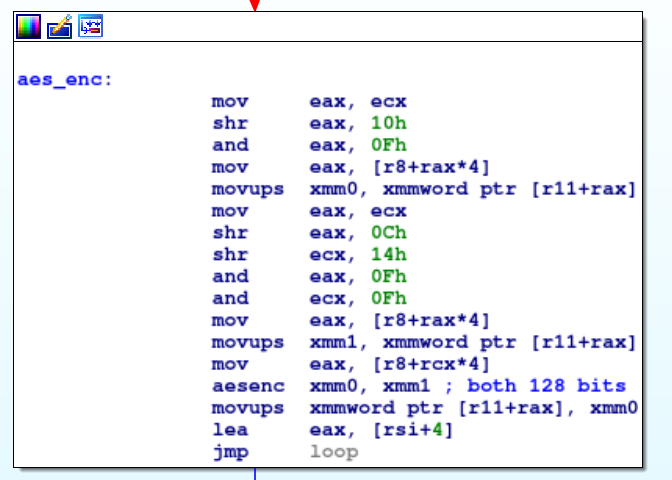
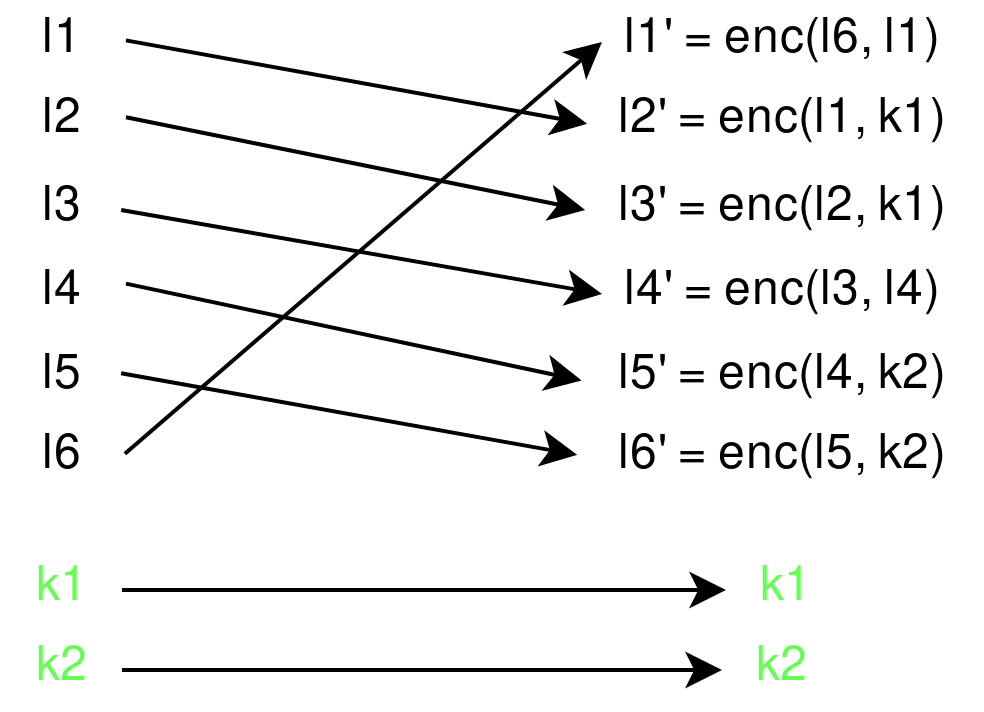
Le chaînage de blocs personnalisé avec décalages circulaires :
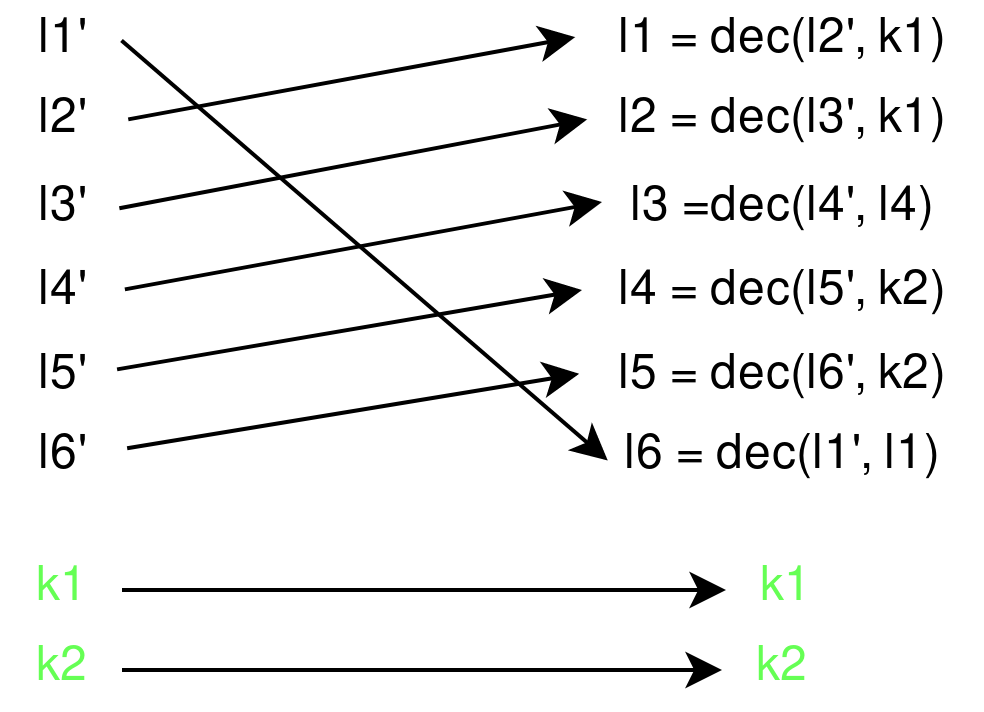
Et l'inverse pour le déchiffrement :
La fonction du keygen :
def generate_serial(username, key):
h = hash_username(username)
serial = decrypt(h, key, rounds=32)
return serialcat input | ./keykoolol
[+] Username: [+] Serial: [>] Valid serial!
[>] Now connect to the remote server and generate serials
for the given usernames.Si vous le faites, soyez plus malin que moi
Les alternatives qui m'auraient fait gagner beaucoup de temps :
- Exécution symbolique (avec angr, miasm ou équivalent)
- Traduction automatisée de toute la représentation intermédiaire
Je n'ai pas essayé ces méthodes, mais ceux qui les ont utilisées ont obtenu des résultats bien plus rapidement.
Références
Restez classe, amateurs de cybersécurité.
FCSC 2020 — Keykoolol — 500 points
Besoin d'un audit de sécurité ou d'un accompagnement sur mesure ?
Découvrir nos services →